


Graduating Your Serverless Monolith Into Microservices
Where to get started when the right time comes

We’ve talked before about why it can be a good idea to get started with serverless following the “serverless monolith” approach.
But as an application (and the team maintaining it) grows, it’s reasonable to start considering adopting a microservice architecture.
Why microservices?
Microservices (if well implemented) can help a team move faster and produce better results.
Microservices increase autonomy, encourage ownership and improve team performance because they reduce blockers and dependencies.
Microservices boundaries
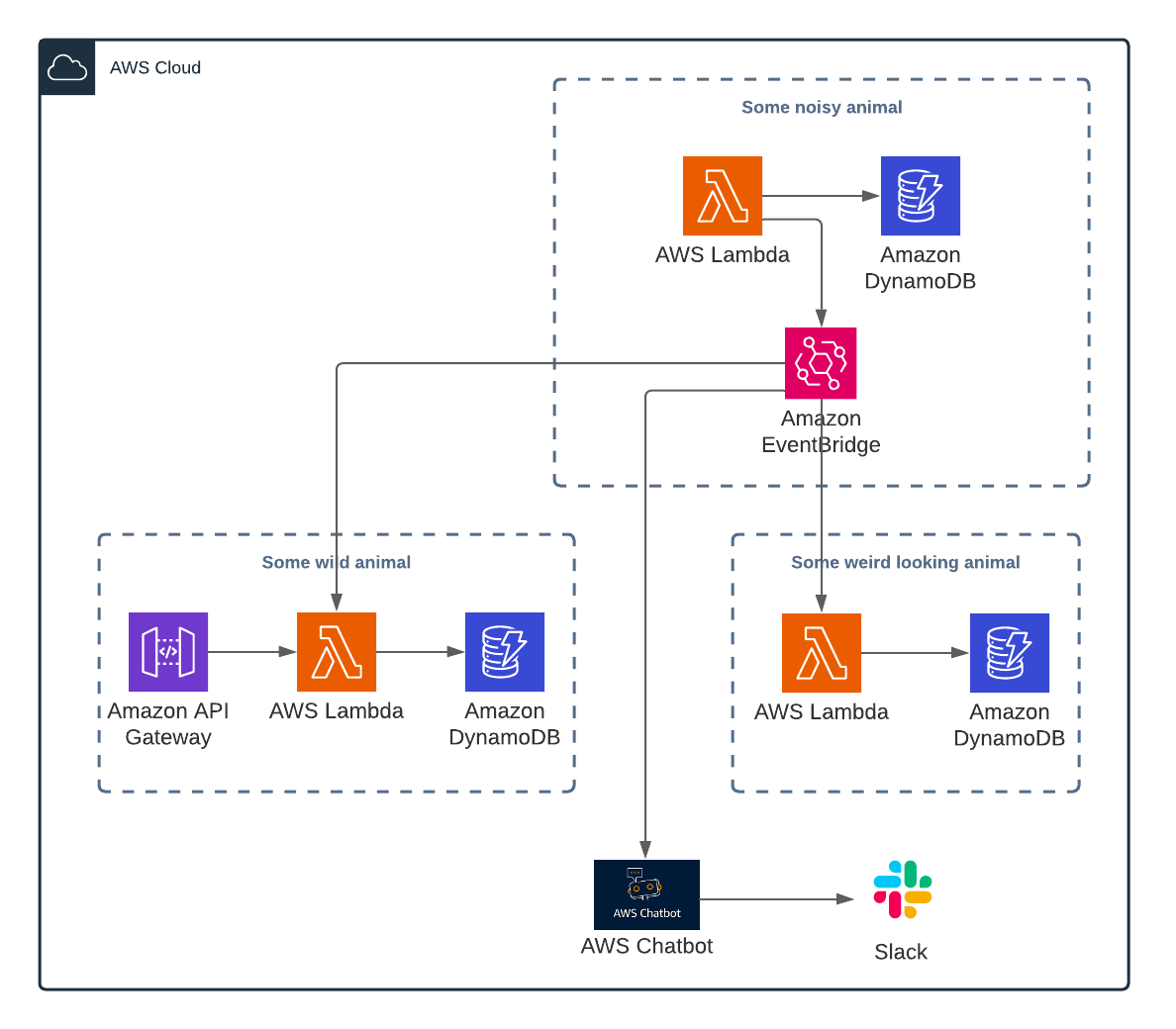
The first thing that I’m going to need to do to transition from a simpler Lambda-monolith to a microservice application is to establish boundaries.
Microservice boundaries are really just a way to denote logical ownership of resources.
So, for example, rather than having a bunch of database tables that every Lambda can access, I can determine that Service X owns all the resources that deal with Users, and Service Y owns all the resources that deal with Products.
If at any point, Service X needs something product-related, it doesn't just grab it from the product table; it needs to send a request to Service Y, which will act as the interface between the two.
Nanoservices
Once I've identified my microservice boundaries, another structure that I've found quite helpful is the idea of nanoservices.
A nanoservice is intended to do only one task at a time and is presented as a single API endpoint.
Let's say I have a Shopping Cart microservice. I could have a nanoservice in charge of adding products, another one dealing with deleting products, etc.
A good rule of thumb is to think of each Lambda as its own nanoservice, whereas a microservice is often going to be made up of multiple Lambdas.

By using the nanoservices approach we get more granular security, faster deployment, and better code encapsulation.
I think that there are a lot of benefits to using nanoservices once one has made the leap into the microservice world. I talked about it a bit more here.